Corpusの概要
2004.1.1
corpusとは、ある特定の方針で集められた、コンピュータ処理可能な文例集のことです。このcorpusを使うと、Non-nativeにはわからない英語の疑問が、たちどころに解消します。
みなさんは次のような疑問を持ったことはないでしょうか?私は、こういう疑問によくぶちあたります。
-
この単語は、自分の専門領域では、辞書の記載とは異なる使われ方をされているのでは?(疑問1)
-
この動詞とこの名詞は一緒に使えるか? あるいは、この名詞とよく使われる動詞は?(疑問2)
-
この単語は今でも一般的か? あるいは、この新しい単語はもう一般的に使えるか?
-
文法的に正しいこの表現は、一般的に使われているか?
しかし、これらの疑問に答えられるのは、ネイティブもしくはネイティブなみに英語に達者な人だけです。場合によっては、ネイティブでも確信を持って答えられないかもしれません。こういった疑問に答えてくれるのがcorpusなのです。
こんな説明をすると何か難しいもののような気がするかもしれませんが、corpusはいたって単純です。要はコンピュータで処理できる文例集(言語不問)です。多くの場合、テキストフォーマットで十分です。たとえば、学会の論文集がテキストになっていれば、立派なcorpusです。そのほか、雑誌の記事や小説など、corpusの種はいくらでもあります。
この文例集であるcorpusをconcordancerと呼ばれるソフト(下図参照)で検索するのです。concordancing programとは、corpusをデータベースとした検索ソフトです。concordancing programの特徴としては、検索した語をその前後を含めて表示できることと、言語学的な統計処理機能を有することがあげられます。
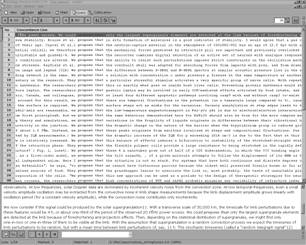
このcorpusとconcordancing program を使うと、先に上げた疑問に対する答えが見つかります。つまり、問題としている表現が一般的に使われているか、ある単語と一緒に使われる形容詞や動詞は何か、などを調べられるのです。
疑問1
proposeという単語を英和辞書で引くと、「that節の中は《米・英正式》仮定法現在,《主に英》should」(ジーニアス英和辞典
第3版)となっています。では、科学技術論文の中で、実際にはどう使われているのでしょう?
科学雑誌Natureに掲載された論文をcorpusとして検索(約300万語)してみると、proposeの後に続くthat節の中でshouldが使われることもなければ、仮定法現在も一般的ではなく、現在形が圧倒的に多いことがわかります。(現在形が正規な用法ということではなく、そのような使われ方が主流ということ)
疑問2
「関係を修復する」は、どう英訳したらよいでしょう?英和辞典で「relationship」を引いても載っていません。和英辞典で「修復」を引くと、”repair,
restore, mend”などが載っていますが、relationshipと一緒に使えるかはわかりません。
そこで、米雑誌TIMEの記事をcorpusとして検索(約340万語)してみると、relationshipは repairやrestoreと一緒に使われることはなく、mendと一緒に使われることがわかります。
このようにcorpusは、使い方次第でどんな辞書や参考書よりも便利なツールになります。