ホームページを
ダウンロードロードする
2004.2.13
オリジナルcorpusを作る手順は、次のようになります。
-
ターゲットのホームページをソフトウェアで一括ダウンロードする
-
ダウンロードしたhtmlファイルを1つに結合する
-
結合したhtmlファイルをテキストファイルに変換する
まず、corpusにしたいホームページのターゲットを決めます。英語圏の雑誌のホームページなどが最適です。自分の専門の雑誌を選ぶとよいでしょう。
ただし、ソフトウェアで一括ダウンロードできるのは、htmlファイルに直接リンクをしているホームページです。Javaを使っていたり、ダイナミックリンクしていたりするページは、有料のソフトウェアでもダウンロードできないことがあります。ターゲットのホームページのリンク先が、abcdefg.html(あるいは拡張子なし)のようなhtmlファイルになっていることを確認してください。
次に、ホームページを一括ダウンロードするソフトウェアを入手します。ソフトウェアには、無料のfreewareと有料のsharewareがあります。有料であれば、それだけ機能が豊富で使いやすくなっています。以下が代表例です。いずれもVector(http://www.vector.co.jp)から入手できます。
freeware: GetHTMLW
shareware: AutoGet, WebAuto
次に、ソフトウェアの設定が必要です。細かい設定はマニュアルを読んでいただくとして、最低限の設定だけを説明します。
まず、プロキシを使ってインターネットに接続している場合は、プロキシサーバーの設定が必要です。たとえば、GetHTMLWであるなら、プルダウンメニューから「設定」→「ISP-Proxy設定」を選択します。すると、次のようなフォームがポップアップしますので、ここで使っているプロキシサーバーを記入します。
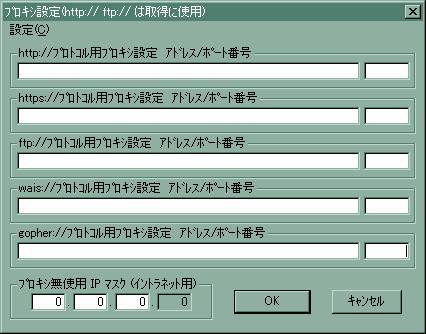
自分がプロキシを使っているかが分からない場合は、お使いのWebブラウザで確認しましょう。Internet Explorerなら、プルダウンメニューの「ツール」→「インターネット オプション」→「接続」のタグ→「LANの設定」のボタンとクリックしていけば、プロキシの設定が表示されます。
次に、ダウンロードするファイルの種類を設定します。入手したいのは文章ですから、htmlファイルやテキストファイルだけです。画像や動画、圧縮ファイルのような不要ファイルをダウンロードしないよう設定しましょう。
GetHTMLWなら、プルダウンメニューから「設定」→「取得条件設定」を選択します。すると、取得条件設定用のフォームがポップアップしますので、「フィルタ編集」というボタンをクリックします。次のような画面がポップアップします。
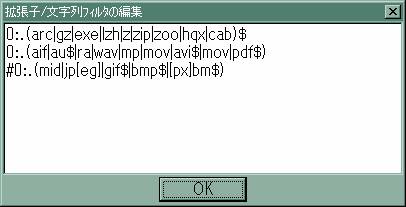
ここで、3行目先頭の#を削除して、OKをクリックします。これで、画像ファイルがダウンロードの対象からはずれました。また、1, 2行目の設定により、圧縮ファイルや動画ファイルはデフォルトで対象からはずれています。
次にダウンロードする手順を説明しましょう。まず、ダーゲットのホームページとして、ここではUSA TODAY(http://www.usatoday.com)を例に取りましょう。実際に、USA TODAYのホームページ全部をダウンロードしようとすると、ファイル量が膨大になりすぎます。ダウンロードするときには、ご自身の専門領域のページの下だけをターゲットにしましょう。例えば、スポーツが専門なら、http://www.usatoday.com/sports/front.htmをターゲットのページとします。
一般的なダウンロード支援ソフトウェア(GetHTMLWも含む)は、デフォルトの設定なら、ターゲットのページ以下だけをダウンロードします。つまり、下位階層へのリンクはたどってダウンロードしますが、上位階層へのリンクはたどりません。http://www.usatoday.com/sports/front.htmをターゲットのページとすれば、http://www.usatoday.com/sports以下だけをダウンロードの対象とします。
次に、GetHTMLWを起動して、プルダウンメニューから「動作」→「WebPage取得」を選択します。すると、次のようなフォームがポップアップしますので、ターゲットのホームページのURLを入力します。
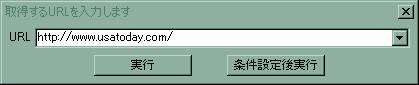
ここで、「実行」ボタンを押せば、ダウンロードが開始されます。次のようなフォームがポップアップして、ダウンロードの状況を報告してくれます。
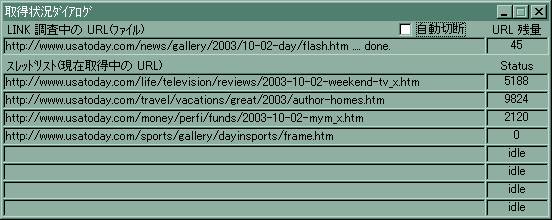
正常にダウンロードできていれば、Status欄の値(ダウンロードしたバイト数)が刻々変化し、スレッドリスト欄のファイル名も次々に変わるはずです。もし、しばらく待ってもこのフォームに何の変化もないようなら、プロキシの設定など、ネットワーク関係の設定が不適切になっているものと考えられます。設定をし直すか、ネットワーク関係に詳しい方にご相談ください。
URL残量欄には、取得しようとするファイル数が表示されます。最初は、トップページにリンクされているファイルだけですから、小さな値です。しかし、ダウンロードを進めていくと、どんどんリンクをたどって、膨大なファイル数になることがあります。
もし、URL残量欄の値が数千にもなるようなら、ダウンロードしようとしているファイル数が多すぎます。ダウンロードに膨大な時間がかかってしまいます。また、ダウンロード先のサーバーにも大きな負荷をかけてしまいます。いったん終了して、ターゲットのホームページを再検討してください。
ダウンロードしたファイルは、GetHTMLWをインストールしたフォルダの下に、www.usatoday.comというフォルダが自動で作られて、その下に保存されます。ターゲットのホームページの階層を再現するように、フォルダが階層構造になっているはずです。
リンクをすべてたどりきって、すべてのファイルをダウンロードすれば、GetHTMLWは正常終了を伝えてきます。もし、ファイル数が多すぎて途中で強制終了しても、それまでダウンロードしたファイルは、上記のフォルダに保存されています。corpusを作るのに十分な単語数(百万語以上)がダウンロード済みなら、途中で終了してもよいでしょう。